

























ANSYS的博客
2022年5月11日
为Ansys Fluent释放gpu的全部力量,第1部分
你下班回家的路上,从纽约到伦敦的航班,办公室里的旧咖啡机,你的公司仍然不会升级……就像计算流体动力学(CFD)模拟一样,所有这些都将从加速中受益。
多年来,高性能计算(HPC)一直是加速CFD模拟的关键推动因素之一,近年来,高性能计算已扩展到图形处理单元(gpu)。
在CFD领域利用gpu并不是一个新概念。gpu用作CFD加速器已经有一段时间了(包括在Ansys流利自2014年以来)。然而,你得到的局部加速度是由问题决定的。最后,未针对gpu优化的部分代码将限制您的整体加速。这就是为什么我们想向您展示当CFD模拟在多个gpu上本机运行时gpu所具有的潜力。
这是我们博客系列的第一部分,“为Ansys Fluent释放gpu的全部力量”,这将演示gpu如何帮助减少仿真时间,硬件成本和功耗。在第一期中,我们将介绍一些层流和湍流问题。随着本系列的深入,物理建模功能也将随之讨论。
32X加速汽车外部空气动力学
对于我们的第一个例子,让我们看看汽车外部空气动力学模拟,它可以变得非常大,非常快-通常超过3亿个单元格。运行这种规模的模拟将需要数千个内核和数天(有时甚至数周)的计算时间。如果有一种方法可以将模拟时间从数周减少到数天或数天减少到数小时,同时还能显著降低功耗,那会怎么样?剧透警告:有,那是通过完全在gpu上运行这些模拟。
可持续性是汽车行业的一个关键问题,世界各地的政府机构都在制定严格的法规。汽车公司一直在评估满足或超过这些规定的一些领域包括:
- 改善空气动力学
- 减少排放
- 使用替代燃料
- 开发混合动力和电动动力系统选项
但是,可持续发展的努力不应该局限于最终产品(在这个例子中是一辆汽车)的操作,这种努力也应该延伸到产品的设计过程中。这包括模拟,我们Ansys希望减少模拟过程中消耗的电量。

汽车外部空气动力学模拟可以通过完全在gpu上运行来加速
对于所示的仿真,我们使用Fluent在不同的CPU和GPU配置上运行基准驱动程序模型并比较性能。我们的研究结果表明,单个NVIDIA A100 GPU的性能比具有80个Intel®Xeon®白金8380内核的集群高出5倍以上。当扩展到8个NVIDIA A100 gpu时,模拟速度可以提高30倍以上。
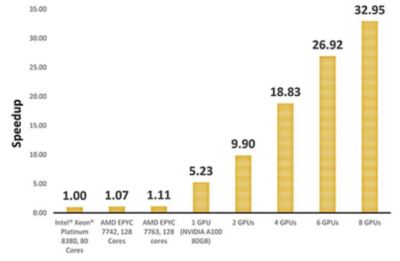
利用gpu加速汽车外部空气动力学模拟
在更短的时间内获得结果使我们的客户更有效率,但它并不止于此:我们还可以通过大幅降低运行此类模拟所需的功率来减少他们的电费(并帮助地球!)。
我们研究了1024个Intel®Xeon®Gold 6242核的CPU集群的功耗,发现功耗为9600 W。与提供相同性能的6 × NVIDIA®V100 GPU服务器的功耗相比,功耗降低了四倍,降至2400 W。
这些基准测试结果表明,与同等HPC集群相比,选择6倍NVIDIA®V100 GPU服务器的公司可以将其功耗降低4倍,这甚至不考虑降低冷却成本以保持服务器室凉爽。
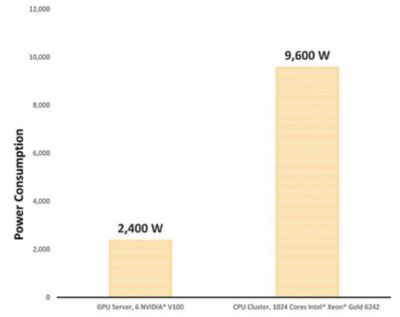
使用GPU服务器时降低功耗
在原生GPU求解器上运行模拟可以对公司的可持续性努力和减少等待结果的时间产生巨大而直接的影响。而不是随便什么结果——这些结果是你可以信任的。在过去的40多年里,Fluent已经在广泛的应用中得到了广泛的验证,并以其行业领先的准确性而闻名。Fluent中可用的CPU和多gpu求解器都基于相同的离散化和数值方法,为用户提供几乎相同的解决方案结果。
下面的两个典型案例是建立良好的CFD验证,模拟了层流和湍流状态的基本原理。这两种情况都详细说明了在gpu上本地解决时用户将获得的准确性。
球体上的层流
文献中有大量的球体流动的实验和数值研究,作为外部空气动力学验证的基本基准。对于第一次测试,我们选择层流条件,其中雷诺数等于100,流体会绕着球体运动在圆柱后面形成定常涡流结构。采用文献中提出的阻力相关性来比较CFD结果与实验数据。
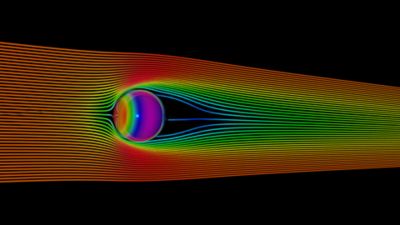
球体基准层流的速度流线和压力分布
如表1所示,本机GPU实现非常准确地计算阻力系数,错误率仅为-0.252%。

表1。阻力系数(Cd)比较
朝后踏步
后向步骤是一个用于测试湍流模型实现的典型问题。这个看似简单的结构显示出丰富的物理性质。在这个测试中,我们重现了Vogel和Eaton建立的实验2入口速度为2.3176 m/s。通过比较沿通道长度不同平面的速度分布与已公布的实验数据,对CFD代码进行了测试。

面向后的步骤的速度矢量
当在cpu上解决时,流畅显示出良好的有效性有实验结果3,4。使用本地的多GPU求解器解决同样的问题为用户提供了几乎相同的结果,如下图所示,因为Fluent中可用的CPU和GPU求解器都是基于相同的离散化和数值方法构建的。
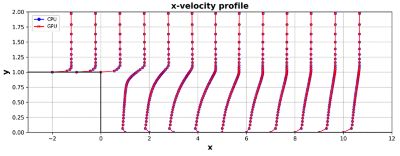
在cpu和gpu上求解后面向步骤的速度剖面结果
参考文献
- Turton r;和Levenspiel, O.,关于球体阻力相关性的简短说明,粉末技术。, 47, 83-86, 1986
- Vogel j.c.和Eaton, j.k.(1985)后向台阶下游的综合传热和流体动力学测量。[j] .中国科学:自然科学,2009(1):1 -9。
- Smirnov, Evgueni & Smirnovsky, Alexander & Shchur, Nikolai & Zaitsev, Dmitri & Smirnov, P.(2018)。后向台阶湍流和传热的RANS和IDDES解的比较。热和传质。10.1007 / s00231 - 017 - 2207 - 0
- 刘建军,刘建军,刘建军,刘建军。(2020)。基于CFD的修正后台阶流体流动数值模拟。国际工程与技术研究杂志。第七卷,第九期
看看Ansys能为您做些什么
看看Ansys能为您做些什么
联系我们
立即联系我们
